 by Shannan
by ShannanThere are several different types of search engines, but crawler-based search engines are by far the most popular. Both Google and Bing are crawler-based search engines and they work by using robots, which are often called “crawlers” or “spiders”, to discover new pages from across the World Wide Web. if you think of the intern as a library and a search engine as a librarian – their role is to find and organise the content on the web. It is agreed that there are three key areas search engines focus on, they are:
-
- Crawling – is what makes a search engine crawler-based and relates to how a search engine can find a page
- Indexing – during indexing search engines analyse page quality and organise the content found
- Ranking – here a search engine determines the position of a web page within search.
How Search Engines Crawl The Web
To find new web pages or entire websites, crawler-based search engine bots will do the following:
- Download a web page that they have discovered.
- Examine the downloaded page and change it into a form that can be read, to identify the hyperlinks on a website, also known as parsing.
- The found URL is added to the crawl queue
- A URL is taken from the crawl queue and steps 1 and 2 are repeated for every link found, which will lead to more links that can be followed.
Search engines discover the initial links by returning to web pages they have already crawled or by crawling a web page that has been submitted to them by a website owner or SEO. This can be done in search engine tools, like Google Search Console, or a crawler will read the XML sitemap.
How Navigation Helps Search Engines Find Your Pages
Ensuring that you’re important pages are within the navigation of a website can help guide search engines to those URLs and ensure that they are crawled frequently, which is helpful when updating important pages. For example an eCommerce website will have product listing pages in the navigation which will ensure that new products are crawled when they are added to them.
Just like an architect would build a house optimal for functionality and space, you need to build a website that is optimal for both crawlers and users. However, including all of your important pages within the nav will make it difficult for search engines to understand the structure of the site. Ensuring that pages to be found in 1-4 clicks from the homepage is a great way to help crawlers discover pages easily. You can achieve this through category pages and frequent internal linking.
And don’t make your users think! Keep your site design simple and intuitive, so your users don’t have to think too hard about how to work their way around.
How Sitemaps Help Search Engines Crawl URLs
A sitemap is essentially a list of web pages on a site that you want Google to crawl. Sitemaps must only contain:
- URLs that return a 200 OK server response – i.e. they are live on a website
- URLs should be indexable for search engines
- Websites can specific when the page was last modified which may help a crawler when a page is updated – as it will recrawl
A search engine will often re crawl an XML sitemap to look for new pages on a website.
This video gives more information about XML sitemaps and its uses.
What is Parsing?
When Google parses a site, it essentially breaks it down and rebuilds it using the instructions given from the various code on the site. Some code it can read fast, such as lightweight languages like HTML. Others, such as JavaScript, are read slower as they tend to be slightly heavier. JavaScript is a difficult
There is some speculation to how Google exactly parses the code and renders sites. They like to keep it close to the chest.
However, we do know that if you have excessive Javascript and other heavy code on your site that covers content, Google will struggle to read it. So, keep it to a minimum.
How Does Google Index the Web (And Make You Visible to Searchers)?
You’ve probably seen me mention the term ‘indexing’ a fair amount now throughout this article and some of you may not know what it means.
So, let me spend a short while explaining it to you and how Google uses indexing to make sure your site appears in the search engine results pages (SERPS).
Indexing is a fancy word for ‘storing’ because that’s exactly what Google is doing when they index your site – storing it on their database.
When Google finds your site one of their crawls (which are constantly happening by the way), if it meets their criteria as a healthy, helpful site, they will include it in their index.
Checking whether your site in the Google index is fairly simple. You simply have to use Google themselves with advanced search parameters.
Go to Google and type in “site:[your site]” and all the indexed pages will come up. 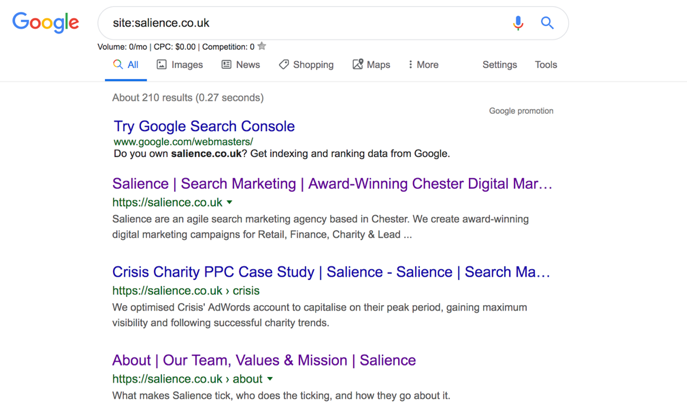
Although this isn’t always the most effective way to check, it is the quickest.
A more efficient way to check your indexation is through Google Search Console. Here you can all sorts of information about your site – it’s a very useful tool indeed.
You can also see how Google has cached your site on its last crawl!
To do this, click the green arrow next to your domain and click “cached”. 
From here, you can see how Google has captured your site.
Why Isn’t My Site in Google’s Index?
Google doesn’t always index everything it finds. Not all website pages make it onto their index.
Sometimes it is just by rotten luck. Other times it’s because there’s an error on the page or it doesn’t look like a high-quality site.
But what errors can stop a page from being indexed?
In general, 4xx or 5xx codes can create problems for crawlers and will result in the page being deindexed as a result. 
4xx and 5xx errors are when either the page cannot be accessed, or the server isn’t responding. In either case, these issues need to be resolved; otherwise the page won’t be indexed.
A simple 301 (permanent) redirect will work perfectly for 4xx error, but for 5xx, you may have to contact your host.
Blackhat and Indexation
If Google notices something “fishy” with your site, you may struggle to get it indexed.
Google is getting smarter every day, especially with their new AI Rank Brain, so tricking the computer is becoming more and more difficult.
As a result, if you are currently diving into the world of Blackhat with keyword stuffing, link cloaking, and PBNs, you might struggle to get a place on the SERPs.
The takeaway message?
DON’T USE BLACKHAT!
How Does Google Read Your Site so You Can Start Ranking?
“All this information about Crawlers, spiders, and indexation is fascinating Lewis, but how does Google read my site so I can rank better?!”
I hear your cries, don’t worry.
But it’s important to get the foundations right; otherwise, you won’t be found by Google (yikes).
However, now you understand that section, let’s dive into how Google reads your site so it can rank you.
And yes, this is the juicy bit, so pay attention.
Content is King… Sorta
You may have heard the phrase “content is king” getting thrown around the SEO community.
The phrase isn’t exactly wrong, but it isn’t completely true either.
Content is what should make up the bulk of your website as it is what Google can quickly understand.
With software such as RankBrain, Google has become very intelligent when it comes to recognising words and written language. Even without RankBrain, Google has a number of methods it uses to read a piece of content.
Here are a few.
Co-occurrence and semantics
Google, not too long ago, released a research paper indicating they use co-occurrence in their efforts of understanding content. This suggests Google utilises words that relate to the main keyword of the page. Primarily, this is to help the speed of the crawling, as Google can then match up different words and associate them to the overall theme of a page. For example, on a page about Richard Branson, there may be words like “business”, “Virgin”, or “Airline”. In the community, these are sometimes referred to as LSI keywords (latent semantic indexing). They are keywords that aren’t synonymous but ones that are related.
TF-IDF
Don’t let yourself get scared away by the complicated nature of this abbreviation. TF-IDF stands for Term Frequency-Inverse Document Frequency. It’s a big fancy word to describe the importance Google gives words that appear frequently on the page. In a nutshell, Google gives less priority to keywords that appear too frequently in the text. This was probably implemented to prevent keyword stuffing during the OG days of Blackhat.
Synonyms and phrase-matching
Unfortunately for Google, language is very fluid and constantly changes. Therefore, Google has to keep up by grouping similar words together, and it does this through synonyms. By doing this, Google can read a page and understand the context of the words, opposed to seeing floating words that have no meaning.
What Else Do They Use?
Google also uses images and title tags to create an impression of your page when reading it.
It’s a pretty comprehensive software if you haven’t noticed already.
However, there are ways you can help Google read and understand the content on your page. One of those ways is Schema.
Schema allows you to tag different sections of content and inform Google on what they’re on. This means that Google has more of a chance at understanding exactly what the page is about.
In addition, if you mark up your content with schema properly, you can also bag yourself a featured snippet at the top of Google (if you’re on the first page).
It’s a relatively new concept that is still being experimented with.
We do have a comprehensive schema guide for ecommerce though if you’re interested!
Either way, by producing content that is easily readable from Google’s end, you can give yourself a boost in the rankings.
However, as indicated by the subheading, content by itself is not the only factor influencing whether you get a first-class ranking.
So Why Isn’t Content the Supreme King?
Content is important, yes, but it isn’t the only key factors Google reads when determining how they’re going to rank your site.
Introducing RankBrain and UX!

https://www.bytestart.co.uk/google-rankbrain.html
If Google had a God, it would definitely be user experience.
In the past few years, Google has put more effort into implementing UX metrics into their ranking algorithm than ever before.
Arguably, they are now using click-through rates and dwell time as ranking signals, so making sure users are finding your content and actually staying on it is just important as writing the content in the first place.
This means you could have a huge piece of content, stuffed with relevant keywords and semantics, but if users are bouncing off your page, Google will slap you down the SERPs.
However:
A lot of these findings have come from correlational studies from the likes of Rand Fishkin and Larry Kim. Nothing has been confirmed by Google for definite.
Nonetheless, there are signs Google is using user experience and engagement as a signal in their algorithm, so you need to be catering content to not only offer answers but also keep users on-page.
This is also mean optimising your meta tags to improve CTR.
Can Google Read Backlinks? (The Truth about Off-Page SEO)
Back in the day, backlinks were everything.
You could literally write a 300-word article and spam it with 100s of comment and forum links, and you’d be at the top of Google by the end of the day.
Now, however, things are a little different.
Even with thousands of backlinks pointing at your site, you can still struggle to rank!
Why is this the case? What happened to the quick ranks?
Unfortunately, Google changed their algorithms, and now backlinks aren’t what they used to be. These days, you not only need volume but quality!
Don’t get me wrong…
Backlinks are still incredibly important, but when compared to content and UX, they’ve been somewhat been left in the dust.
There are a million and one ways to build backlinks, but without solid content, you won’t get very far.
Aim to produce high-quality pieces of content that can be linked to and shared among the community they represent.
The days of rapid backlink production are long gone, so focus efforts on the long-term.
Wrapping It All Up
So there you have it.
A complete guide on how Google reads your site.
Here’s a quick recap:
- Google crawls pages around the web and will try its best to crawl all of your site (unless you’re not helping it!)
- Google, if it likes your site, will index you and start showing you in their SERPs (Yay!)
- If you want to start ranking, you need to write content that is easily read by Google and help it out using Schema
- Don’t forget to account for UX and user engagement, as RankBrain is forever watching
- Backlinks are important and you need them to rank. However, focus your efforts on awesome content and the backlinks will come naturally
Hopefully, you learnt a thing or two from this guide.
If you need any help with your SEO, feel free to reach out!
Our Sources






