 by Alex
by AlexRead on for a basic log file analysis that assumes some knowledge of SEO, Microsoft Excel formulas, and Screaming Frog SEO Spider (or other crawling software).
I’ve provided example findings from a server log file analysis of salience.co.uk.
Jump to:
- Why is Log File Analysis Important?
- Software used for our Log File Analyses
- Server Log Files Request (Email Template)
- Log File Analysis Process
- Example Findings from salience.co.uk Log Files
- Final Thoughts & Useful Links
Why is Log File Analysis Important?
Guiding search bots (such as Googlebot and Bingbot) around a website is an important aspect of technical SEO. You want to send crawlers to the pages you want to rank in search engines while keeping them away from unimportant pages and especially pages that shouldn’t be indexed (such as filter URLs, test and template pages).
A well structured main menu with a clear hierarchy that leads to products is one way of helping search bots (and website visitors). E.g: Beds > Double Beds > Jameson Natural Pine
Most large websites have a crawl budget – a limited time search bots spend on a website each day. If crawl budget is wasted on pages that shouldn’t be crawled, it can lead to the website not being crawled or indexed as well as it should be. Generally, the more pages a website has, the greater benefits a log file analysis can provide. Though we’ve seen indexation improvements on websites with as few as 150 pages indexed in Google (e.g. new pages crawled and indexed quicker after removing low value pages that Google crawled regularly). Like removing thin pages during a content review, a log file analysis can find low-quality pages that search engines crawl but don’t deem worthy of decent indexation. Google also considers website quality as a whole when ranking individual pages.
On one log file analysis, I found order pages that numbered in the thousands, responsible for a significant chunk of crawl budget. According to crawls we ran on the website, the pages weren’t linked internally. They weren’t indexed in search engines and didn’t show in Google Search Console. Without the log files, the order pages wouldn’t have been found.
Distilled has a section on the benefits of log file analysis: Why should you do log analysis?
One good point is “By seeing where Google spends its time on your site you can prioritise the areas that will affect it the most.”
Software Used for Our Log File Analyses
- Screaming Frog SEO Spider
- Screaming Frog Log Analyser
- Microsoft Excel (may not be suitable to analyse large amounts of data – mine struggles at around a million rows)
Server Log Files Request (Email Template)
Obtaining the correct log files from web developers or clients isn’t always straightforward. I use the following email request at Salience: We analyse website server log files (ideally twice a year, or more if needed) to gain insights from how Googlebot and Bingbot crawl a website. The log files can help highlight search indexation issues we wouldn’t otherwise be aware of. To be most useful, at least 28 days data is required. We require the following to be enabled on server logs from before the start date of the data we’ll analyse:
- IP of each hit (so we can verify whether a search bot hit is genuine).
- See all hits (e.g. from the main server and any caching proxies or subdomains).
- Protocol, Domain and Hostname Logging (e.g. to distinguish between http and https URLs, subdomains, non-www vs www prefixed URLs etc).
- The Referrer of each hit.
- If they’re not enabled by default, date & time, URL requested, and the server response code are also required.
To reduce file size (and avoid the possibility of sharing any personal data), we can receive filtered data showing hits from only Googlebot (Googlebot) and Bingbot (bingbot – no capital ‘b’ in their string if filtering is case sensitive), with no other filtering or modifications applied. We verify we’ve received the correct amount of data based on crawl stats in Google Search Console. Please zip files for quicker download. Log file type is unimportant as long as we can access the contents as they’d appear in the server logs. E.g. common filetypes we receive are .log, .txt or a zipped format.
Log File Analysis Process
Website Crawl
I start a log file analysis by crawling the website with Screaming Frog SEO Spider, following all internal links (including nofollow, XML sitemaps and hreflang if relevant) and linking with the Google Analytics API for recent organic traffic data (over the same data range as the log file data).
Analysing Log File Data with Log Analyser and Excel
I import the log files into Screaming Frog Log Analyser and verify genuine bot hits (Project > Verify Bots if the log files are already imported), then filter to show Verified bots only:
I paste verified search bots into an Excel template. If you don’t use suitable spreadsheet software, check the “Useful Links” section below for further information on how powerful Screaming Frog Log Analyser is. You can find actionable information with Log Analyser alone.
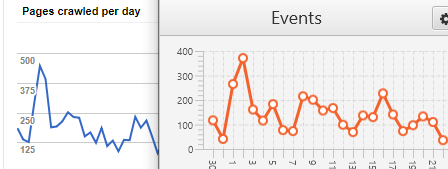
It’s worth comparing the graph on Log Analyser’s Overview tab (Events panel filtered to Verified, All Googlebots) to the Crawl Stats graph in Google Search Console. They rarely match exactly, but if they differ wildly I’ve found that log file data is missing from the files provided. Here’s one example of a graph matching enough for me to be confident the data is correct enough (Google Search Console on the left and Log Analyser on the right):
Added to the default columns (from the Log Analyser export) in our Excel template are Parameter, Crawl Issue, Canonical Mismatch, Indexability, and Organic Traffic (see screenshot below).
To isolate query strings (making it easier to scan and filter them), the following formula is in the Parameter column (assuming the first URL is in cell A3):
=IFERROR(RIGHT(A3,LEN(A3)-FIND("?",A3)),"")
Once the Parameter column data has populated, select it and Copy > Paste Values over the original data (to speed up data filtering).
When the crawl (started earlier) finishes, it’s exported and dragged into the Imported URL Data tab on the Log Analyser interface. The crawl data automatically matches to the URLs found in the log file(s) (Log Analyser > URLs tab > View: Matched with URL Data). This data is exported and pasted into a separate Excel tab, using a VLOOKUP to populate the Canonical Mismatch (from the Canonical Link Element 1 column), Indexability, and Organic Traffic columns:

What follows isn’t an exact science; we’re looking for a good estimate of crawl budget waste and/or the time search bots spend on low value URLs. We’re only taking the number of URLs and events into account. For example, we could estimate bandwidth wastage from the Average Bytes column. File size is taken into account later. E.g. if URLs with a high file size are often hit by search bots, we may recommend optimising the URLs (e.g. they could be oversized images or PDFs).
In the Crawl Issue column of our spreadsheet, the following URLs are marked with a “y” to signify URLs we might not want search bots to crawl:
- Highlighted as Non-Indexable in the Indexability column.
- Not 200 OK in the Last Response column (e.g. 301, 404, 410, 500).
- Contains URL parameter (excluding correctly paginated URLs and parameters that aren’t used for content we do want indexed in search engines. The latter is a rarity on modern websites).
- Cart, account, wishlist, conversion, thank you etc. (excluding the main login URL, as they’re often clicked to from search engines).
- Should be nofollowed but are crawled.
- Internal search result pages.
- Duplicate URLs (e.g. lowercase and uppercase versions).
- Test or template pages.
As I’m doing the above, I make note of issues to highlight or investigate later. E.g. of URLs we’d prefer to be crawled less but mostly not at all, or to be fixed (e.g. 404s that should return 200 OK).
It helps to filter out URLs already marked with an issue, ordering by the URL and Parameter columns to spot patterns. It’s not possible to list all issues, but they won’t all fall into the above list. E.g. something I spotted when scanning through salience.co.uk log file data was most URLs were duplicated with a suffix /feed/ folder. These URLs weren’t linked anywhere internally yet accounted for 32% of the URLs causing crawl budget waste.
On an Overview tab of our log file analysis Excel template, formulas populate pie charts summarising crawl budget waste:
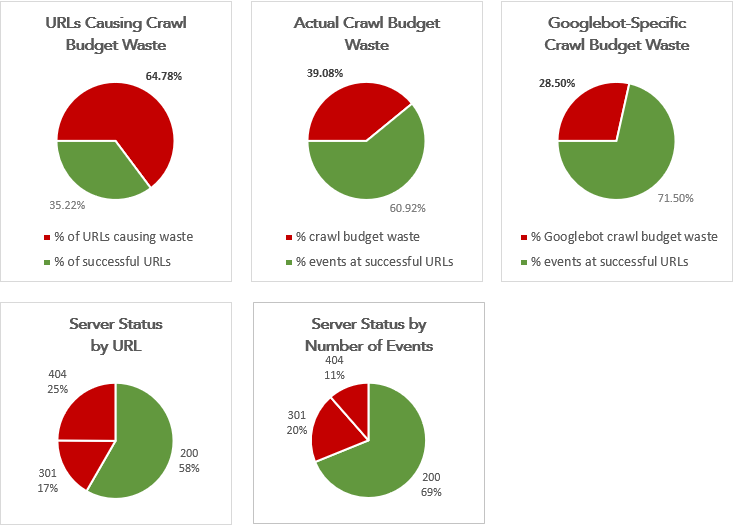
The visuals help get our points across to clients and are much easier than looking at rows of data.
Prioritising issues
When prioritising issues, it can help to order them by the number of events. For example, if a 404 Not Found URL is hit by Googlebot 1,000 times a month, it’s a bigger waste of crawl budget than a 404 that’s barely crawled.
Generally, search bots should be crawling the most important pages (usually top-level categories on e-commerce websites) most frequently than other pages. Even on near-perfect websites, this rarely lines up with expectations. Sometimes one page may be crawled way more than another (e.g. due to high authority backlinks or social traction). Investigate if none of the most important pages are crawled most often. E.g. are internal links hidden behind JavaScript? Is the hierarchy of the website unclear and difficult for search bots to follow?
Consider the organic traffic data we crawled with Screaming Frog SEO Spider when prioritising. E.g. big gains often come from improving pages/content that receive lots of traffic. Is a page that receives lots of organic traffic not crawled often? Maybe it’s hidden deep in the website’s structure, and would receive more traffic if it was more prominent. Related product/post links can help.
In Log Analyser, the Directories tab shows the most crawled directories. They’re often folders that contain JavaScript, CSS and images, which makes sense as bots need to crawl those files to render pages. After that, the most crawled directories should generally contain the pages that are important to rank.
Sometimes it’s worth breaking down findings by date such as:
- Did 404 Not Found errors increase suddenly?
- Are regularly updated pages crawled often? E.g. Category pages that frequently include new products or are subject to seasonal offers – is Googlebot finding them quickly?
Also look for inconsistent server responses (Log Analyser > Response Codes tab > Inconsistent filter), something I notice more with websites that are dynamically rendered.
Example Findings from Salience.co.uk Log Files
Our recent domain migration from insideonline.co.uk to salience.co.uk was an opportunity to show some useful data provided by a log file analysis. None of the following examples were found in a normal crawl of the website using Screaming Frog SEO Spider or DeepCrawl. They’re all common issues.
Most Crawled URLs
Overall, our most crawled URLs were as expected; our homepage, contact page, Insight page, and various blog posts and sector reports.
Exceptions were old CSS and JavaScript files, which continue to be crawled by Googlebot despite consistently returning a 404 Not Found status. I’ll check the status of these in a future log file analysis. Using the 410 Gone instead of 404 Not Found server status may have removed them from search bot crawls quicker.
/feed/ URLs
The URLs with a /feed/ folder were, according to Dave, one of our developers: “a default WordPress function to generate XML feed data on all pages/posts.” They’ve been prevented with a custom function.
In the next log file analysis for the Salience site, I’ll check if the number of search bot hits to these URLs has reduced.
Interestingly, Bingbot hit some of these URLs multiple times daily, whereas Googlebot didn’t crawl some at all during the log period. I generally find Googlebot to be cleverer when figuring out whether URLs are worth crawling or not. You can see in the pie charts screenshot above that Googlebot crawl budget waste is much less than crawl budget waste from combined search bots.
However, Googlebot is much ‘better’ at finding URLs I’d prefer it didn’t find (such as URL fragments in JavaScript).
Conversion Pages
Two form completion pages were crawled by bots. These aren’t linked internally or indexed in search results, and we don’t want them indexed.
We disallowed them in robots.txt.
Tag URLs
Many WordPress /tag/ URLs that existed at insideonline.co.uk were crawled on the salience.co.uk domain by Bingbot (mostly) and Googlebot.
We deleted the tags within the WordPress dashboard so they all return 404 Not Found. Over time, search bots should crawl these URLs less (410 Gone can remove URLs from Google’s crawl schedule quicker).
Search Pages
We don’t have an onsite search, yet Bingbot and Googlebot crawled /search/ URLs. We made sure these return 404 Not Found.
URL Parameters
utm_ parameters are commonly used for tracking purposes. If such utm_ URLs are linked internally on websites, we advise the client updates them to the canonical link without the utm_ parameter. The salience.co.uk utm_ URLs are barely crawled by search bots. But to keep things clean, we disallowed them in Google Search Console (feature removed from Search Console in 2022):

Some parameter use that may lead to crawl budget waste is inevitable. E.g. A version number on a JavaScript or CSS file such as ?ver=1.2 could indicate fingerprinting is used. Old versions will be crawled for a short time even if they 301 redirect or return 410 Gone.
Final Thoughts & Useful Log File Analysis Links
The more log files analyses you do, the more patterns you’ll see and the quicker you’ll spot issues.
It can be interesting to compare search bots. Bingbot, for example, seems much more inefficient than Googlebot. Bingbot may regularly crawl URLs that haven’t returned a 200 OK server status for years, whereas Googlebot figures out the URLs aren’t important and crawls them less frequently or not at all.
However, Googlebot finds more URLs you don’t want it to find, which can be problematic. URLs hidden in JavaScript, for example. Links:
- The Ultimate Guide to Log File Analysis was my introduction to log file analysis a few years ago. It remains one of the best posts on the topic, and it’s kept up-to-date.
- 22 Ways To Analyse Logs Using Screaming Frog Log File Analyser
- How to: Read a web site log file
- A Complete Guide to Log Analysis with Big Query – even if you don’t use Big Query, there’s some excellent information here, including obtaining log files with the correct data.
If you have any more questions about Log File Analysis, get in touch or comment below. [salience_cta heading=”All a bit technical?” copy=”We’ll help maximise your crawl budget” image=”” background=”https://salience.co.uk/wp-content/uploads/Challenge-Us_Background.png” link=”https://salience.co.uk/services/seo-agency/” button_copy =”Your Free Audit”]






